.avif)

Apache Iceberg has become the table format of choice for building open data lakehouses. It solves long-standing problems around ACID transactions and engine interoperability.
The table format itself is standardized, but what is often overlooked when making architectural decisions is the catalog layer - the component that tracks and exposes table metadata.
Your catalog can influence query performance, access control, and which engines can write to your tables. It also determines how much vendor lock-in risk you take on.
This breakdown examines what catalogs do, how the REST specification has impacted them, and how to evaluate your options.
How Iceberg Catalogs Work
Every Iceberg deployment requires a catalog to manage transactions and track metadata.
Iceberg tables store data in Parquet files, with metadata stored in separate metadata files. Each time a table is modified, Iceberg writes a new metadata.json file. Over time, you accumulate versions: v1.metadata.json, v2.metadata.json, and so on. The catalog is responsible for tracking which metadata.json file is the current one.
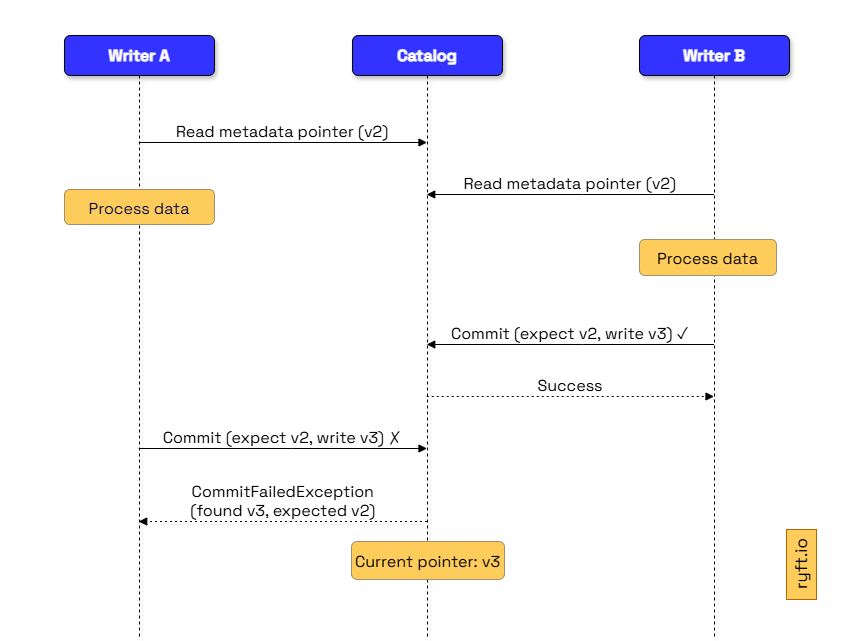
When Spark or Trino needs to read a table, it asks the catalog for the current metadata pointer. When a writer commits new data, the catalog performs an atomic compare-and-swap: it reads the current pointer, verifies it hasn't changed, then updates to the new metadata file.
This compare-and-swap handles concurrent writes. When two writers commit simultaneously, one succeeds and the other fails with a commit conflict. The catalog is also responsible to determine whether a specific client can access a certain table, and manage the access control of the data.
The REST Catalog Specification
Before the REST catalog spec, each catalog needed engine-specific support. Hive Metastore required a Java client, while AWS Glue needed SDK integration. Custom catalogs required adding external modules to every engine's runtime.
The Iceberg REST Catalog specification (introduced in Iceberg 0.14.0) standardized how engines interact with catalogs through HTTP-based APIs. Any engine supporting the REST spec can work with any REST-compatible catalog.
All major Iceberg implementations - Java, Python, Rust, and Go - support the REST Catalog specification. Engines can read and write tables without embedding the catalog, and catalog functions like permissions, optimizations, and validations run server-side instead of being duplicated in each engine.
The REST spec has become the standard across products that work with Iceberg tables. Dremio, Snowflake, Google BigLake, AWS Glue, and Unity Catalog all support the REST Catalog spec, so engine choice can follow workload requirements rather than platform restrictions.
How to Evaluate Iceberg Catalogs
Catalogs differ in how they implement and support different capabilities. These are the key points to consider when comparing them:
1. RBAC (Role-Based Access Control)
Access control determines who can read or write data, create or drop tables, and manage table configuration. Some catalogs, like Unity Catalog and Apache Polaris provide native table level access. Others like AWS Glue and Hive Metastore rely on external systems like AWS IAM or Apache Ranger.
Integration with existing identity providers matters. This includes LDAP, OAuth, or SAML. If your catalog can't connect to your current auth system, you'll end up managing separate identities.
2. Access Auditing
Beyond controlling who can access tables, you need to track how the tables are being used. Audit logs are a compliance requirement for most production systems.
AWS Glue, for example, integrates with AWS CloudTrail to track requests to the catalog. Hive Metastore and Apache Polaris require external monitoring or custom instrumentation to track activity.
3. Deployment & Scale
Most catalogs handle 5-10 concurrent clients per table without issues, but some start showing contention or slower commits as concurrency grows.
Glue depends on AWS API limits that vary by account and region. Hive Metastore runs into database contention as commits lock rows. Stateless catalogs like Polaris or Nessie scale horizontally by adding instances behind a load balancer, or by provisioning more resources.
Serverless or managed catalogs offer easier operation and scaling. If on-premise or custom tuning is necessary, self-hosting an open-source catalog is an option, though it demands maintenance and resource provisioning for scaling.
4. Neutrality & REST Support
One of the main benefits of Iceberg is its engine interoperability. However, some catalogs limit the engines that can write or read from them.
Choosing a fully open catalog allows your lakehouse architecture to be fully flexible and future-proof.
Full REST catalog specification support means any engine can read and write tables without proprietary SDKs. Some catalogs implement the complete spec while others have partial support or require specific engine integrations.
5. Product Maturity
When selecting an Iceberg catalog, prioritize solutions that are mature, production-ready, and widely adopted, as the catalog space is rapidly evolving. A popular choice is more likely to incorporate new Iceberg features quickly. If you opt for an open-source tool, assess the activity and size of its community to make sure bugs are resolved and new features are adopted quickly.
Iceberg Catalog Options
Your catalog choice depends on the infrastructure and workload requirements. At a high level, catalogs fall into a few categories.
Legacy Catalogs
Legacy lakehouses often use catalogs that originally supported older lake architectures, and adapted Apache Iceberg later on.
The most prominent example is Hive Metastore, which was the original catalog for Apache Hive, and later adapted for Iceberg.
Use it only if you're migrating from Hive and when the switch would be more disruptive than keeping it in place. For new deployments, pick a modern catalog.
Cloud Vendors
All major cloud providers now offer an Iceberg catalog of their own. Choose these when your architecture and access are fully incorporated into one cloud provider.
The clearest example is AWS Glue, a data catalog fully managed by AWS. Access is managed via IAM, with auxiliary services like AWS Lake Formation for advanced access control.
Microsoft offers an Iceberg catalog named OneLake deeply integrated with the Azure and Fabric ecosystems, while Google offers BigLake Metastore for GCP lakehouses based on GCS.
Open Source Catalogs
As part of the Iceberg ecosystem, many catalogs are developed open-source.
The most popular catalog in this category is Apache Polaris (incubating), which was originally open sourced by Snowflake. Polaris follows the REST catalog specification and has an active community that continuously adds advanced features like advanced RBAC and support for other open table formats.
Other open source catalogs include:
- Unity Catalog - an open-source version of Databricks’ proprietary catalog
- Nessie - A Git-style version control catalog
- Lakekeeper - offers advanced access control
- Apache Gravitino - a geo-distributed data catalog with Iceberg support
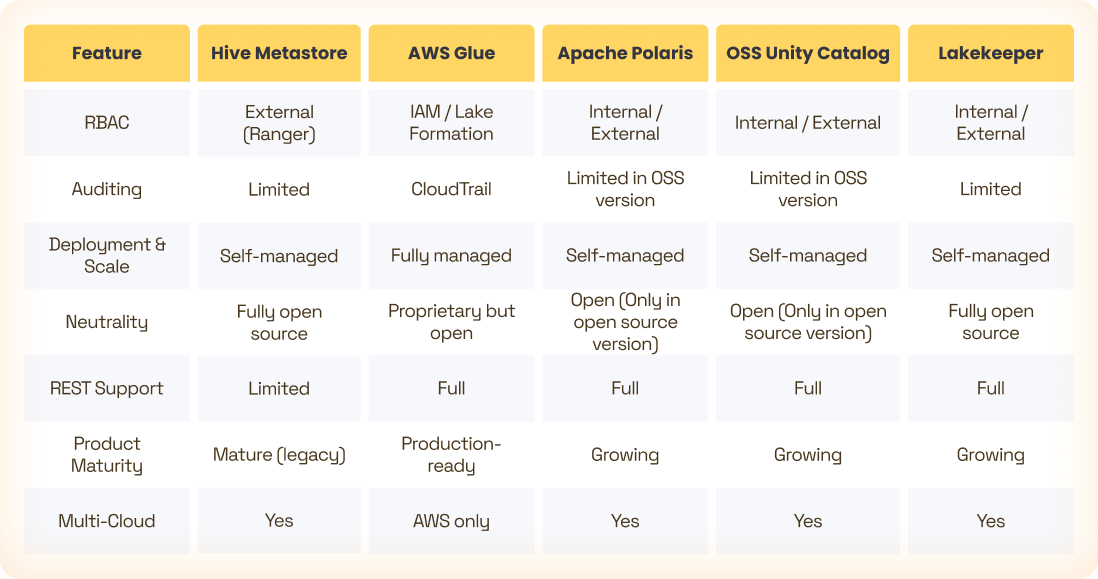
Feature Comparison
Wrapping Up
Iceberg catalogs are a core part of any modern lakehouse. Most catalogs today implement the REST spec, and fulfill the basic requirements of handling metadata and coordinating commits. However, differences in deployment, monitoring, and access control, are critical when choosing the right one. Focus on openness to avoid vendor or cloud lock-in, and on product maturity to ensure new capabilities land quickly and reliably.
The responsibility of catalogs is expected to grow even more with new community proposals such as:
- FGAC (fine-grained access control) - defining row-level and column-level access policies (e.g., “user X can only access rows where region = Y”).
- Server-side planning - shifting scan planning into the catalog, so optimizations happen centrally instead of in each engine.
The catalog is a central piece of your architecture and affects many aspects of your lakehouse. Understanding the differences will help you choose the option that best supports your architecture and long-term plans.
Browse other blogs
.png)


Unlocking Faster Iceberg Queries: The Writer Optimizations You’re Missing
Apache Iceberg query performance is often limited long before a query engine gets involved. In a joint post with Firebolt, we break down why writer configuration, file layout, and continuous table maintenance matter most.
.avif)

.avif)