

Commit conflicts in Apache Iceberg are one of those problems that seem rare - until you start operating at scale. The first time a long-running compaction job fails after hours of compute, or a CDC pipeline spends half its time retrying commits, you realize this isn’t a corner case. It’s a core operational challenge that directly impacts cost, latency, and reliability.
This post covers what commit conflicts are, why they happen, and how to fix them without creating new problems in the process.
Why Commit Conflicts Matter
In Iceberg, multiple concurrent writers – streaming ingestion, compaction, CDC merges, and deletes – all operate independently. That independence is part of Iceberg’s design. But when several of these writers target the same table, conflicts scale fast.
At small scale, retries handle the occasional overlap. At large scale, retries turn into endless loops: compaction jobs fail after hours, streaming pipelines fall behind, and delete operations never complete.
These failures mean:
- Pipeline failures: Streaming or CDC pipelines encountering repeated conflicts fail entirely, stopping data writes and breaking downstream dependencies.
- Wasted compute time: a single failed compaction can burn thousands of cluster-hours.
- Higher query costs: un-compacted tables accumulate small files that make queries slower and more expensive.
- Compliance risk: failed deletes mean data that should be gone remains accessible.
What Causes Commit Conflicts
Iceberg uses optimistic concurrency control. Each writer assumes it’s the only one modifying the table and only checks for conflicts at commit time using an atomic compare-and-swap on the table’s metadata pointer.
Here’s what happens:
- Writer A starts processing with snapshot version 2.
- Writer B finishes first and commits, moving the pointer to version 3.
- Writer A tries to commit, expecting version 2 - but finds version 3. Iceberg rejects it with a CommitFailedException.
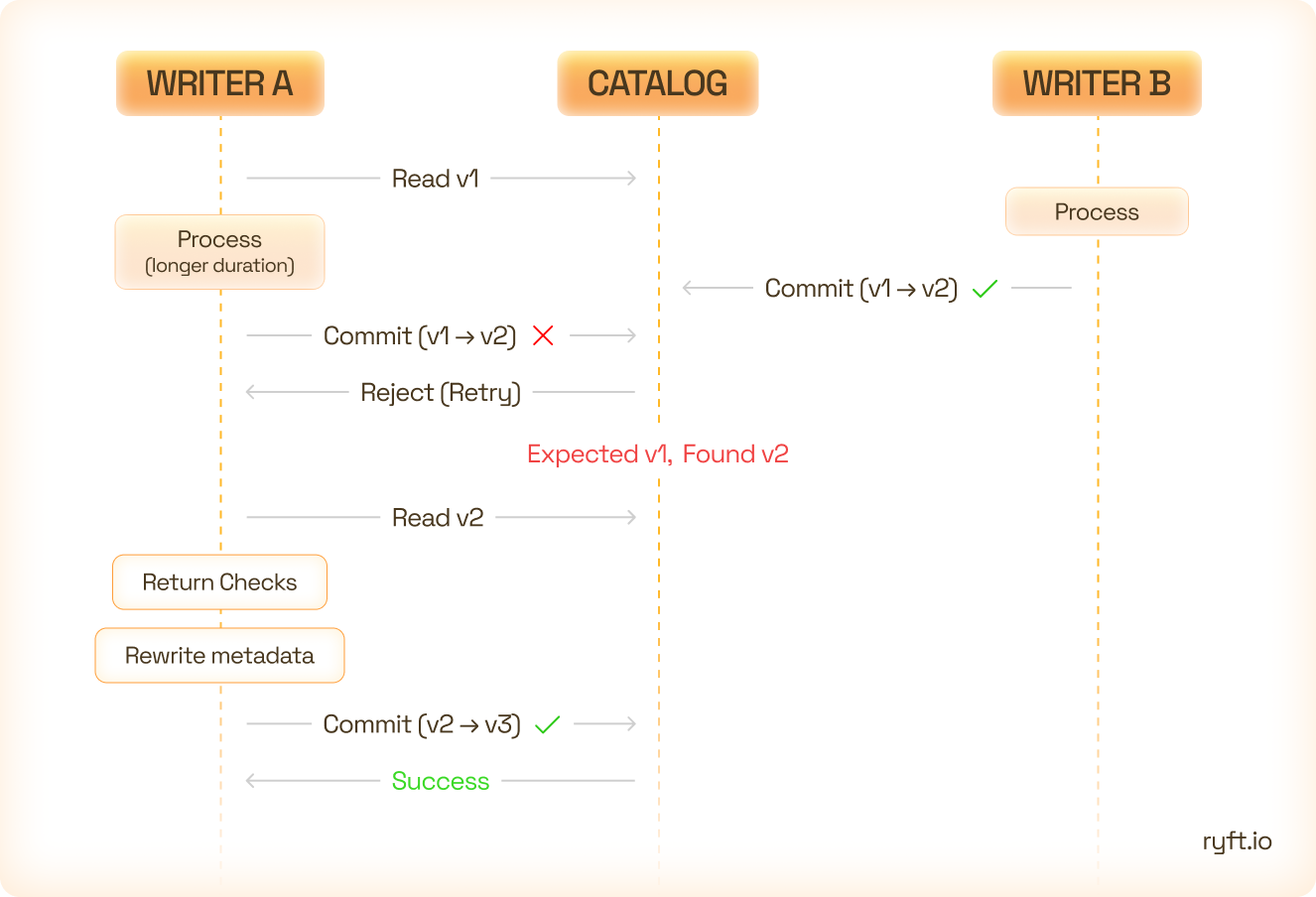
By design, this protects table integrity. But at scale, it also exposes two distinct types of conflicts.
Metadata Conflicts
Metadata-only conflicts happen when another writer updates the table metadata (for example, by adding new files or statistics) without touching the same data files. Iceberg can resolve these automatically by refreshing metadata and retrying the commit.
Default retry settings - four attempts with exponential backoff from 100ms to 60s - work well for small to medium workloads. Once concurrency increases, those defaults stop being enough.
Data Conflicts
Data conflicts occur when two writers modify the same data files or partitions. These can’t be resolved automatically. The entire operation must restart.
This is what makes commit conflicts painful: a compaction job or merge that runs for two hours can fail seconds before completion, wasting all that compute time. As concurrency grows, so does the ratio of unresolvable data conflicts.
Common Conflict Patterns at Scale
The three scenarios below account for 90% of production commit conflicts:
Compaction During Active Writes
A compaction job rewrites many small files into larger ones. If your streaming pipeline keeps writing to the same partition during that process, you’re guaranteed to collide.
Example:
You compact data for event_date = '2025-10-10' for two hours, while your ingestion job commits 47 micro-batches to that same partition. When compaction tries to commit, it finds version N+47. Iceberg rejects it - data conflict.
The result: two hours of compute, zero results. The small files remain, and the next compaction attempt is even slower.
Deletes on Live Data
Compliance or cleanup deletes can run for tens of minutes across large tables. If ingestion continues writing new data into those same partitions, the delete job fails.
That means compliance-sensitive data stays in your system longer than it should - or you halt ingestion to guarantee deletes, losing fresh data in the process.
CDC and MERGE Workloads
CDC pipelines and merge operations are especially conflict-prone. They perform upserts across many partitions, often in parallel.
Even small overlaps between concurrent merges trigger data conflicts. The result is high retry rates, longer latency, and significant wasted compute.
The Compounding Cost Problem
Once conflicts start happening, they create a feedback loop.
Failed compactions leave small files behind. More small files make future compactions slower. Longer jobs mean larger conflict windows, leading to more failures. Query performance degrades, costs rise, and the cycle continues.
A table that costs $10 per query when healthy can easily climb to hundreds per query when compaction falls behind.
How to Fix Commit Conflicts
The way to address commit conflicts depends on workload patterns, table layout, and how concurrency is managed. In production, this is done through careful job timing, partition design, and retry configuration.
1. Enable Partial Progress for Long-Running Jobs
For long-running jobs like compaction, the worst-case scenario is losing hours of work to a conflict near the end. Enabling partial progress changes that.
CALL system.rewrite_data_files(
table => '{table}'
options => map('partial-progress.enabled', 'true', 'partial-progress.max-commits', 10)
)With partial progress, Iceberg commits work in chunks. If a conflict occurs near the end, only the last chunk retries.
Consideration: Each partial commit creates a snapshot. You’ll need to manage snapshot retention more actively:
- Set
history.expire.min-snapshots-to-keepand/orhistory.expire.max-snapshot-age-msto control snapshots buildup
Use this setting when the cost of retrying outweighs the cost of extra snapshots.
2. Shrink the Conflict Window
Sometimes the solution is just to accelerate the running job by doing less. Smaller file groups complete quicker, reducing the time a job stays vulnerable to conflicts.
CALL system.rewrite_data_files(
table => '{table}'
options => map('max-file-group-size-bytes', 1073741824)
)Also, tune retry behavior for high-concurrency environments:
commit.retry.num-retries=8
commit.retry.min-wait-ms=200
commit.retry.max-wait-ms=120000More retries and longer backoff periods help smooth out transient metadata conflicts without overloading the catalog.
Again, this comes with a consideration: more frequent commits mean more snapshots. Balance accordingly.
3. Avoid Compacting Active Partitions
This single adjustment eliminates most conflicts in streaming environments. Don’t compact partitions currently receiving writes.
CALL system.rewrite_data_files(
table => 'events',
where => 'event_date < current_date()'
);Your streaming job writes to today’s partition; your compaction job targets older partitions that are stable.
For CDC workloads, apply the same idea. Track which partitions actually received updates and compact only those. Compacting everything, every time, just creates unnecessary conflict exposure.
Detecting Conflict Symptoms
You can usually spot conflict problems before they cascade.
1. Excessive Retries
Check your job logs for repeated CommitFailedException.
grep "CommitFailedException" /var/log/spark/* | wc -lIf you’re seeing dozens per day on a single table, your writers are fighting each other.
2. Snapshot accumulation
SELECT COUNT(*) FROM events.snapshots WHERE
committed_at > current_date - INTERVAL '1' DAY;More than 1000 snapshots per day on a single table might indicate partial progress misconfiguration.
3. File count per partition
SELECT partition, COUNT(*) AS file_count FROM events.files
GROUP BY partition ORDER BY file_count DESC;High file counts mean compaction is falling behind. Each query opens more files, scans more metadata, and costs more.
Conclusion
Commit conflicts are a natural part of Iceberg’s optimistic concurrency model. At small scale they’re easy to miss; at large scale they’re the main reason compaction, deletes, and merges fail.
Managing them means keeping conflict windows short, jobs predictable, and partition boundaries stable. With this in place, concurrency stops being a problem and becomes just another part of running Iceberg in production.
Browse other blogs
.png)

Unlocking Faster Iceberg Queries: The Writer Optimizations You’re Missing
Apache Iceberg query performance is often limited long before a query engine gets involved. In a joint post with Firebolt, we break down why writer configuration, file layout, and continuous table maintenance matter most.
.avif)

.avif)