.avif)

Apache Iceberg V3 is a huge step forward for the lakehouse ecosystem. The V3 specification was finalized and ratified earlier this year, bringing several long-awaited capabilities into the core of the format: efficient row-level deletes, built-in row lineage, better handling of semi-structured data, and the beginnings of native encryption.
These new capabilities get a lot of attention, but the conversation often skips over a question that matters just as much:
How ready is V3 in practice?
The honest answer is: it depends entirely on your engines. Some environments already support V3 well. Others aren’t close yet.
This post breaks down the major features, the current state of implementation, and what this means for real adoption.
The Major V3 Features
Deletion Vectors
Deletion vectors attach row-level delete information directly to data files, avoiding the pileup of positional delete files and making deletes far more predictable and scalable for delete-heavy workloads.
Status:
- Adopted in most engines that implement V3
- Stable read/write behavior in Spark, Flink, and several vendor engines
- Likely the most production-ready feature in the V3 family
Row Lineage
Row lineage introduces stable row identifiers and version metadata. This simplifies incremental processing, CDC, auditability, and debugging across complex pipelines.
Status:
- Adopted in most engines that implement V3
- Exposure and user experience varies
- Mature enough to rely on in V3-compatible stacks
VARIANT
VARIANT is one of the most awaited additions to the spec - a native semi-structured type rather than dumping JSON into a string column.
However, current support is partial:
- Several engines already support the VARIANT data type, namely Spark, Flink, Starburst Galaxy, and Databricks SQL
- Yet even in the Java reference implementation, there’s still a gap around variant shredding - an optimization that allows engines to extract specific paths from the main variant to their own column, so they can be scanned and pruned individually using column statistics
- Parquet is standardizing semi-structured encodings downstream, which will give engines a reliable, shared representation to optimize against
Geospatial Types
V3 also introduces geospatial types, which are particularly important for teams working with location data.
Status:
- Not available as a datatype in most common engines
- Available with dedicated extensions like Apache Sedona
Encryption
V3 adds the building blocks for table-level encryption across data and metadata.
Status:
- Foundations exist
- Not widely supported - only in Spark/Flink
Engine Support: Where V3 Actually Works Today
Below is a realistic, engine-by-engine overview, including feature breakdown.
Apache Spark
Spark currently has the most complete and most widely deployed V3 support.
- Deletion vectors: supported
- Row lineage: supported
- VARIANT: partial (no shredding)
- Geospatial: supported with extensions
- Encryption: early
Starting with Spark version 4.0, Spark is the engine that can run V3 most reliably today.
Apache Flink
Flink’s Iceberg integration quickly caught up to the Spark implementation, and ships V3 support for the core features.
- Deletion vectors: supported
- Row lineage: supported
- VARIANT: partial (no shredding)
- Geospatial: supported with extensions
- Encryption: early
Flink adoption is accelerating, particularly for streaming use cases.
Databricks
Announced V3 beta support several months ago, enabling:
- Deletion vectors
- Row lineage
- VARIANT (with limitations)
Some limitations exist:
- Some types (e.g., geospatial) not yet available
- Column default values are not supported
If you’re fully on Databricks, V3 is already practical - within the documented limits.
AWS (Glue, EMR, S3 Tables)
AWS also recently announced V3 support, enabling:
- Deletion vectors
- Row lineage
New data type support varies by engine (e.g. EMR 7.12, running Spark 3.5.6, does not support VARIANT).
Amazon Athena
Athena does not support the V3 spec yet.
This is significant because Athena is one of the most widely used SQL engines in AWS environments. Its lack of V3 support is a real blocker for many organizations.
Trino / Starburst
Status is mixed:
- Starburst Galaxy announced V3 support a few months ago, including deletion vectors, row lineage and variant type support. It’s also one of the only engines to support the geospatial data types
- However, OSS Trino still lacks V3 support
If Trino is a major engine in your stack, V3 adoption will most likely need to wait.
Snowflake
Snowflake has significantly contributed to the V3 spec development, with emphasis on the VARIANT data type.
V3 support in Snowflake-managed Iceberg tables is not yet publicly available.
Python (PyIceberg, DuckDB, Pandas ecosystem)
The Python ecosystem supports basic V3 reading. Writes are still limited.
If Python is critical for your ingestion or analytics flows, V3 adoption will likely not be possible today.
Other Engines
Several other popular engines - such as ClickHouse, BigQuery, StarRocks, and Dremio - currently expose only V1/V2 Iceberg functionality. Their public roadmaps either don’t mention V3 yet or list it as future work. That’s not surprising; many of these engines only adopted Iceberg recently, and V3 requires deeper integration.
For organizations that rely heavily on any of these systems, full V3 adoption will likely need to wait.
Feature Support by Engine
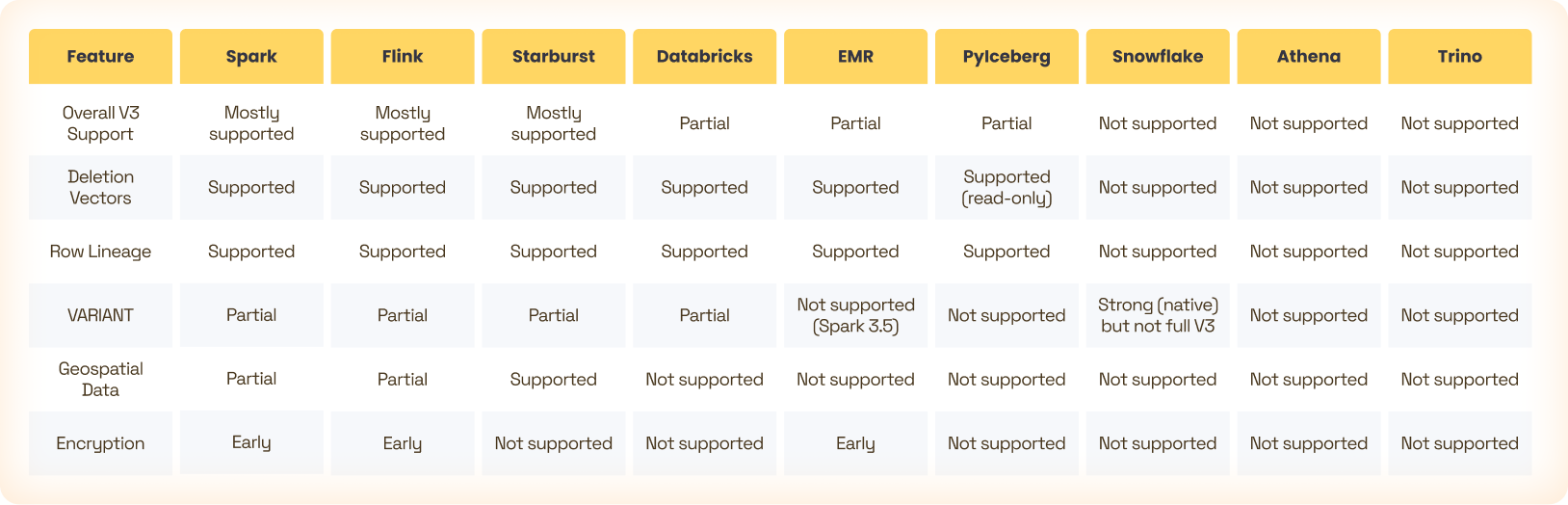
So Can You Adopt V3 Today?
For most organizations, the answer is not yet, for one simple reason:
Some of the most widely used query engines, including Athena, Trino, and Snowflake, do not support V3 today.
You should consider V3 adoption if Spark or Flink is your primary engine, and your downstream readers can already handle V3.
In most other environments, it's recommended to wait and monitor query engine support as the ecosystem evolves.
Conclusion
Iceberg V3 is a major milestone for the Iceberg community. Deletion vectors improve performance significantly, the new data types enable more advanced data models, and the encryption works sets the foundation for stronger security.
But broad ecosystem support isn’t there yet. Several major engines can’t read or write V3 tables yet, and several features (VARIANT shredding, encryption, geospatial data) still need more time to mature.
V3 will definitely become the default format - but most teams will need to wait a bit longer before V3 becomes a safe default for production.
If you want help evaluating your environment or building the right adoption strategy, Ryft can help. We’re working with teams across the community and can help you determine when and how V3 should fit into your lakehouse roadmap.
Disclaimer: This analysis reflects the state of V3 support at the time of writing to the best of our knowledge. The ecosystem is moving quickly, and details may change as engines evolve. If you spot an inaccuracy or an important nuance we missed, reach out at hi@ryft.io.
Browse other blogs
.png)


Unlocking Faster Iceberg Queries: The Writer Optimizations You’re Missing
Apache Iceberg query performance is often limited long before a query engine gets involved. In a joint post with Firebolt, we break down why writer configuration, file layout, and continuous table maintenance matter most.
.avif)

.avif)